SonoWorld: From One Image to a 3D Audio-Visual Scene
CVPR, 2026
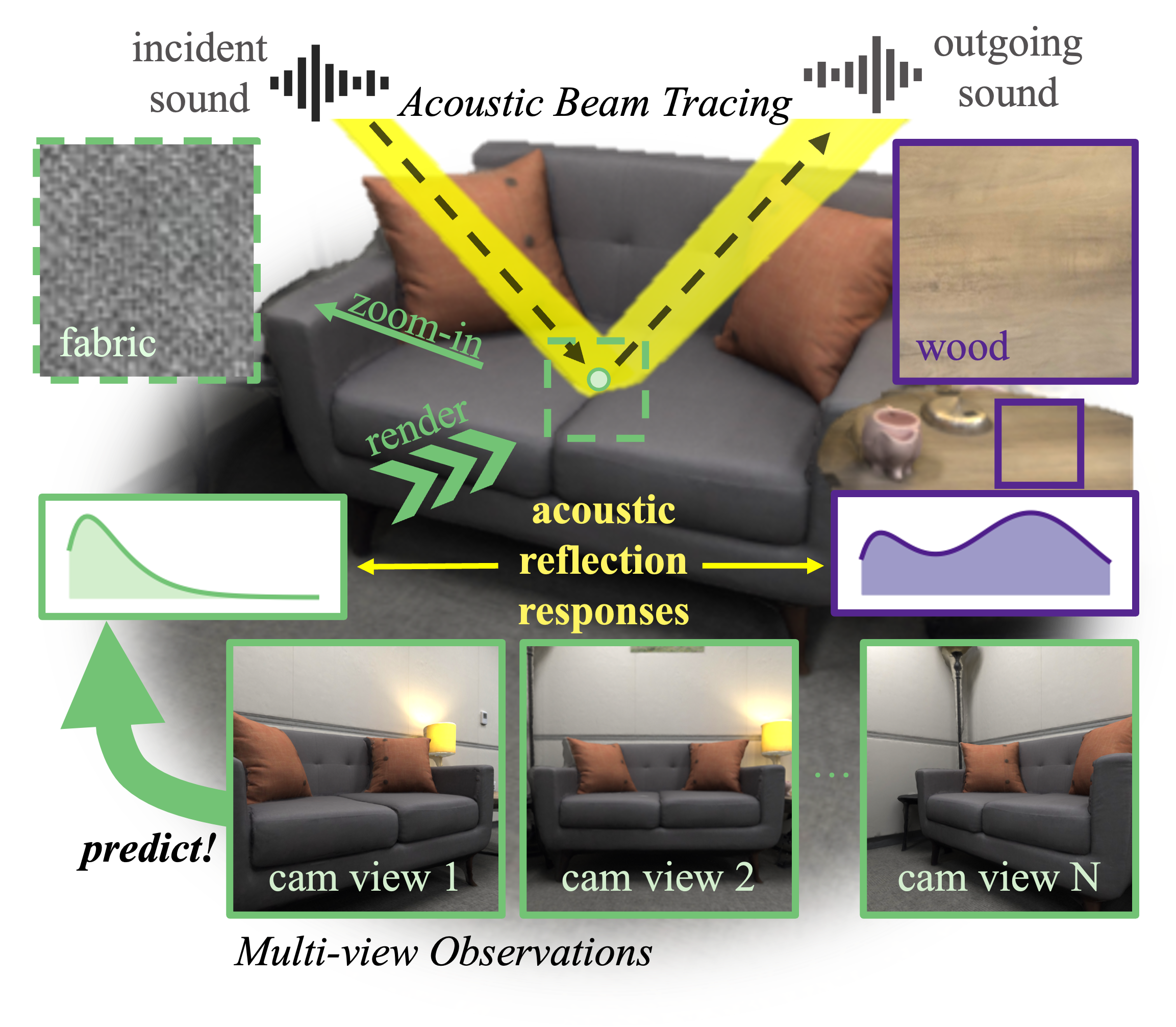
A first generative framework for creating explorable 3D audio-visual scenes from one image, with spatial audio grounded in scene semantics and 3D geometry.